AMPED: Adaptive Multi-objective Projection for balancing Exploration and skill Diversification
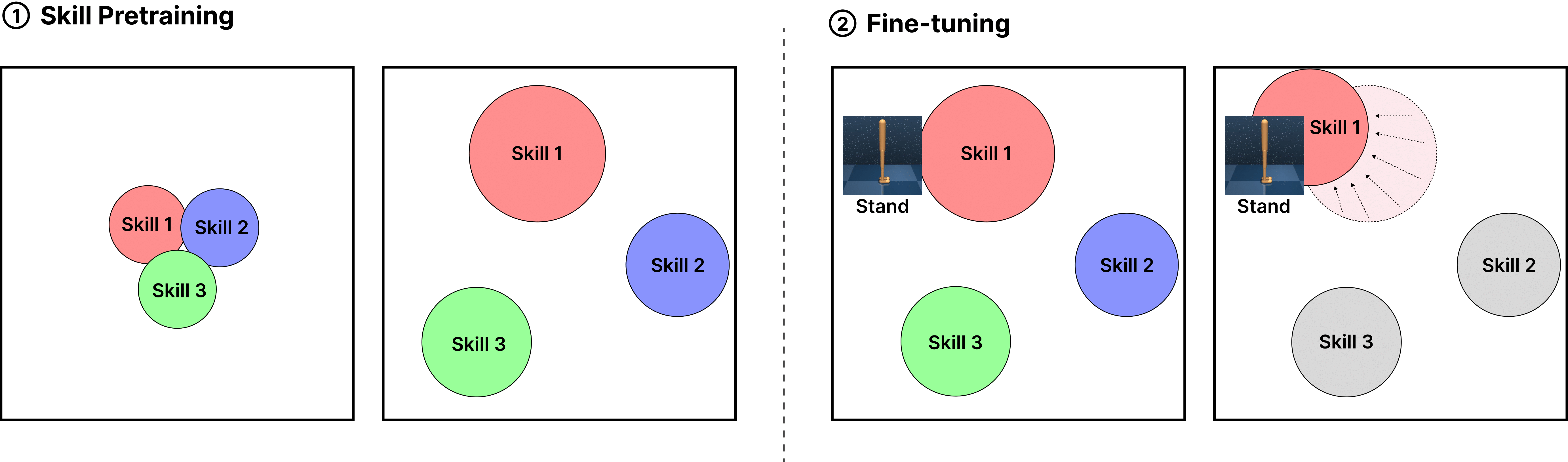
AMPED is a skill-based reinforcement learning algorithm designed to explicitly balance exploration and skill diversity.
Overview
- AMPED is a skill-based reinforcement learning (SBRL) framework that effectively balances exploration and skill diversity, enabling generalizable skill acquisition.
- AMPED is modular and generalizable. Built on standard actor-critic architectures, each component, RND and entropy-driven exploration, AnInfoNCE-based diversity, gradient surgery, and an SAC-based skill selector, can be seamlessly integrated into other actor-critic frameworks with minimal architectural modifications.
- AMPED is performant. On the Unsupervised Reinforcement Learning Benchmark (URLB), AMPED consistently outperforms strong baselines such as CeSD, ComSD, and BeCL across a wide range of challenging locomotion and manipulation tasks.
Idea
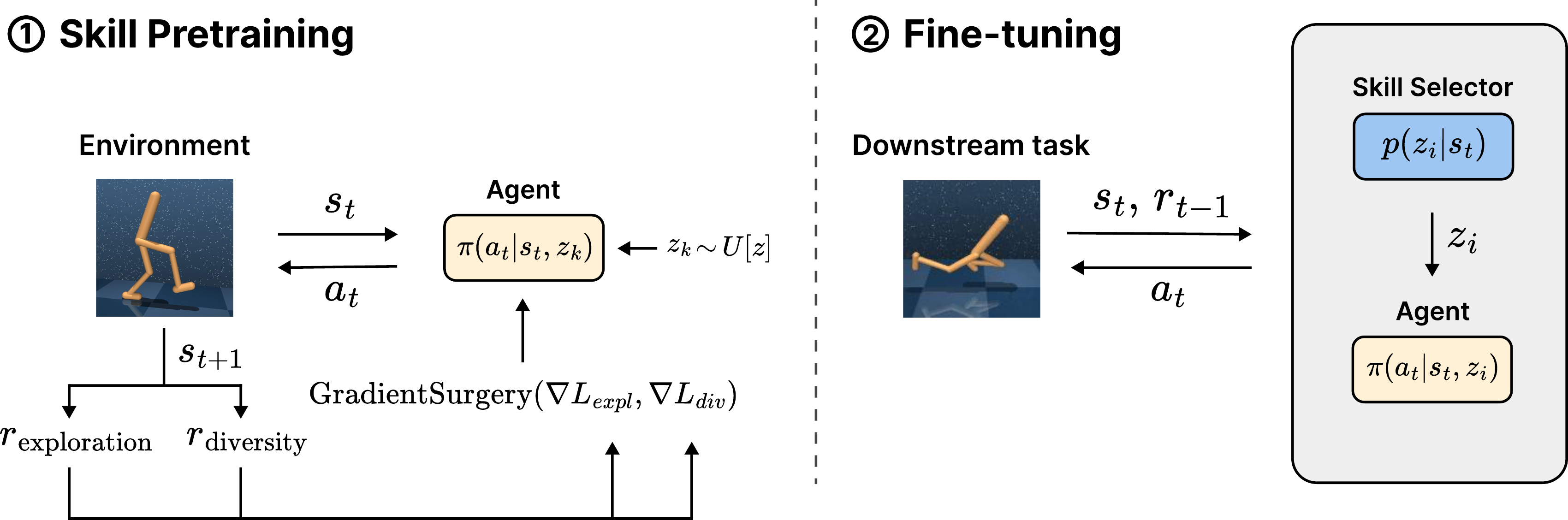
- We propose AMPED, a principled framework that unifies exploration and skill diversity via gradient-level balancing and adaptive skill reuse.
- During skill pretraining, the agent learns a diverse repertoire of behaviors by optimizing both RND and entropy-driven exploration and contrastive skill separation, with gradient conflicts resolved via PCGrad.
- In the fine-tuning phase, AMPED employs a skill selector trained via reinforcement learning (e.g., SAC) to dynamically choose skills based on task-specific rewards.
- This two-stage structure allows AMPED to decouple unsupervised pretraining from task-specific learning, leading to better sample efficiency and generalization.
Algorithms
Algorithm 1: Gradient Surgery (Click to see the full algorithm)

This procedure resolves gradient conflicts between the exploration and diversity objectives. If a negative inner product is detected between their gradients, one is projected onto the orthogonal complement of the other. This ensures that the two objectives do not interfere destructively during optimization.
Algorithm 2: Unsupervised Pretraining with Intrinsic Rewards (Click to see the full algorithm)

The agent collects diverse experiences by sampling skills and optimizing both exploration (via entropy and RND) and skill diversity (via contrastive learning). Intrinsic rewards are computed and their gradients are combined using gradient surgery, enabling stable pretraining without manual loss balancing.
Algorithm 3: Fine-tuning with Extrinsic Rewards and Skill Selection (Click to see the full algorithm)

In the downstream phase, a learned skill selector picks the best skill for the task based on the current state. The agent executes actions using the selected skill, and both the policy and selector are updated using extrinsic rewards. This adaptive reuse enables efficient skill transfer.
Experiments
1. URLB Environments
We evaluate AMPED on the Unsupervised Reinforcement Learning Benchmark (URLB), which spans diverse tasks involving locomotion and manipulation. These experiments demonstrate that AMPED learns diverse and reusable skills in high-dimensional control settings.
Locomotion Tasks

Stepping forward

Backward somersault

Getting up from ground

Backward somersault

Clockwise rotation

Upside-down recovery
Manipulation Tasks

Left reach & grasp

Right reach & grasp

Upward lifting
2. Maze Environments
We evaluate AMPED in Tree Maze and 2D Maze environments to assess the spatial coverage and discriminability of the learned skills through visual analysis.
Tree Maze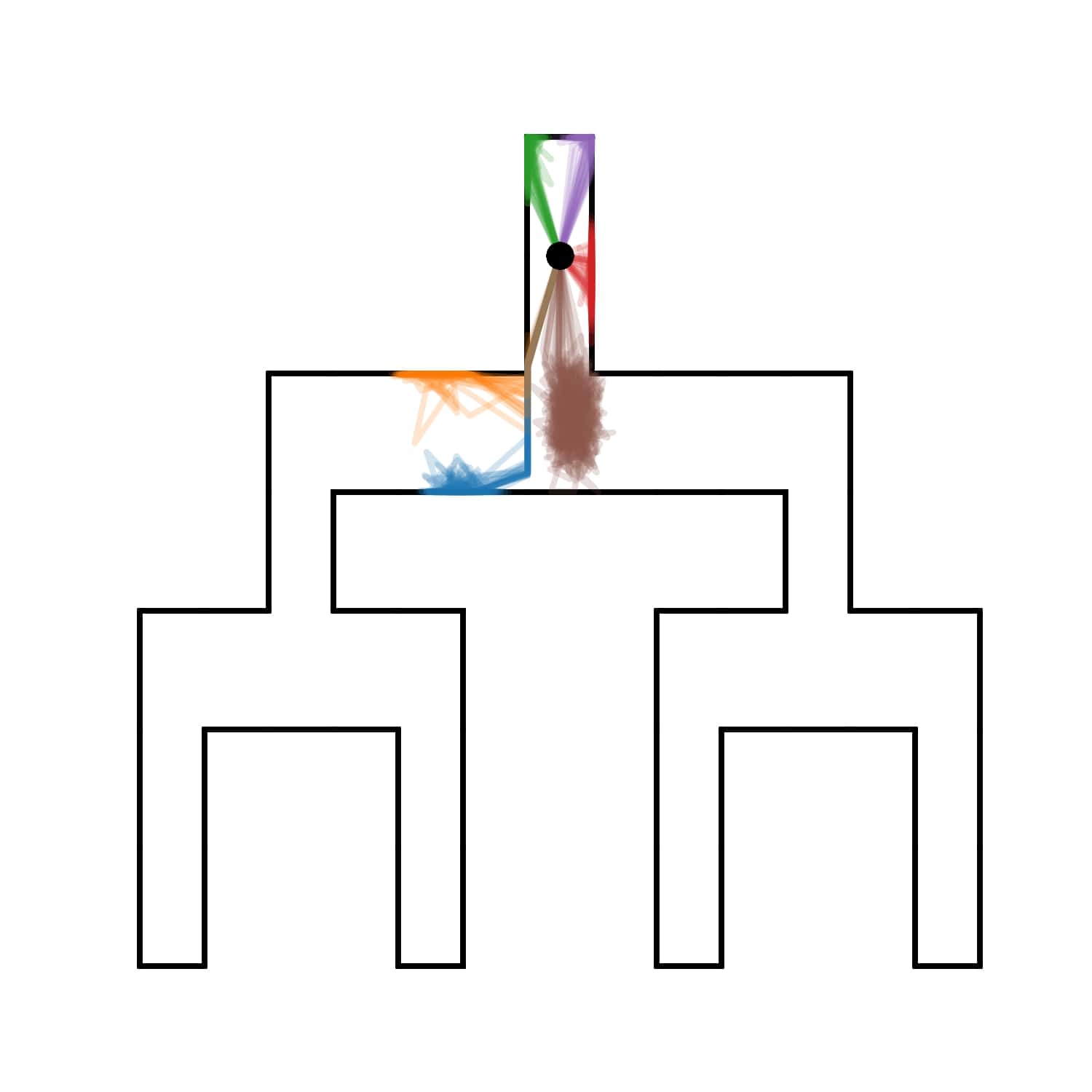
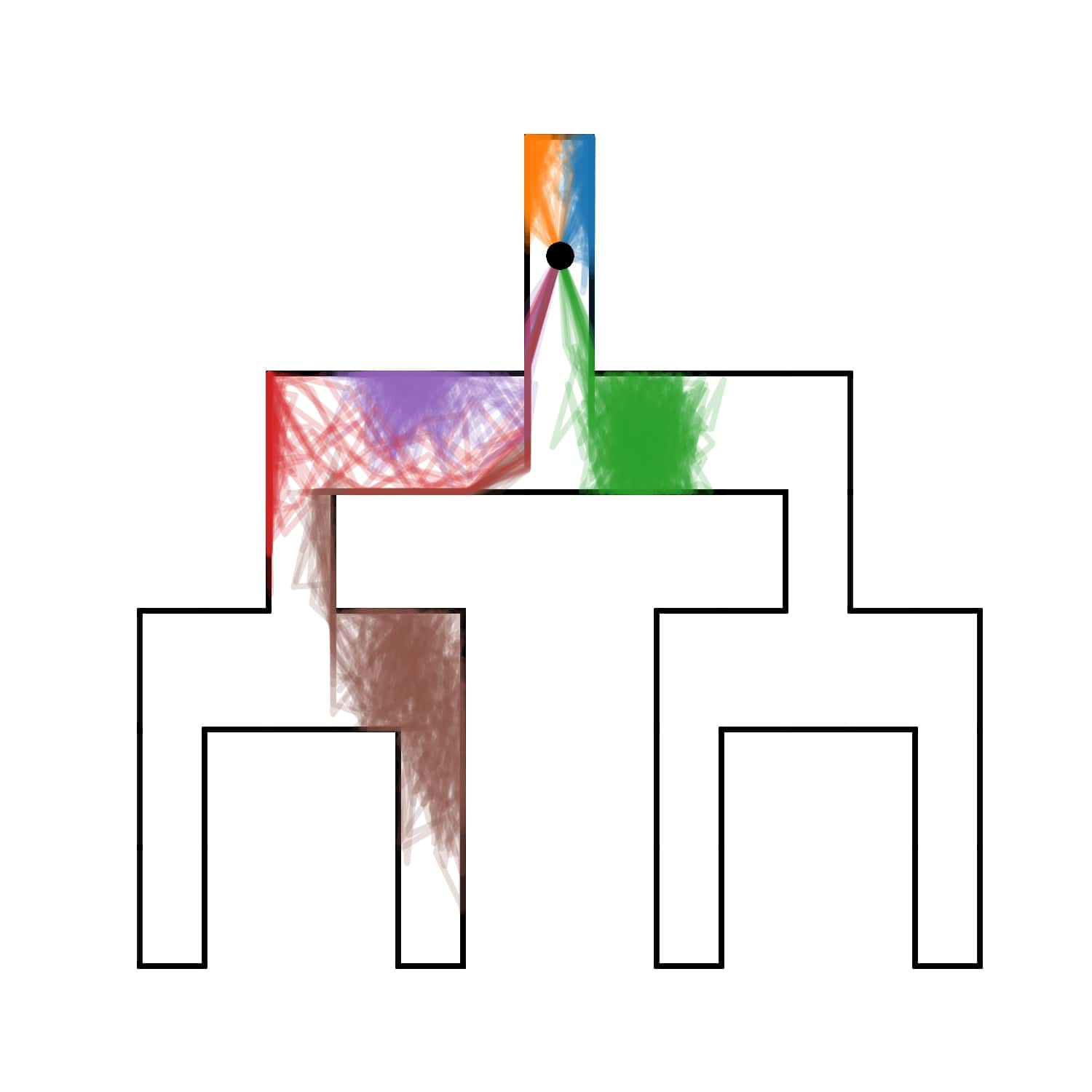
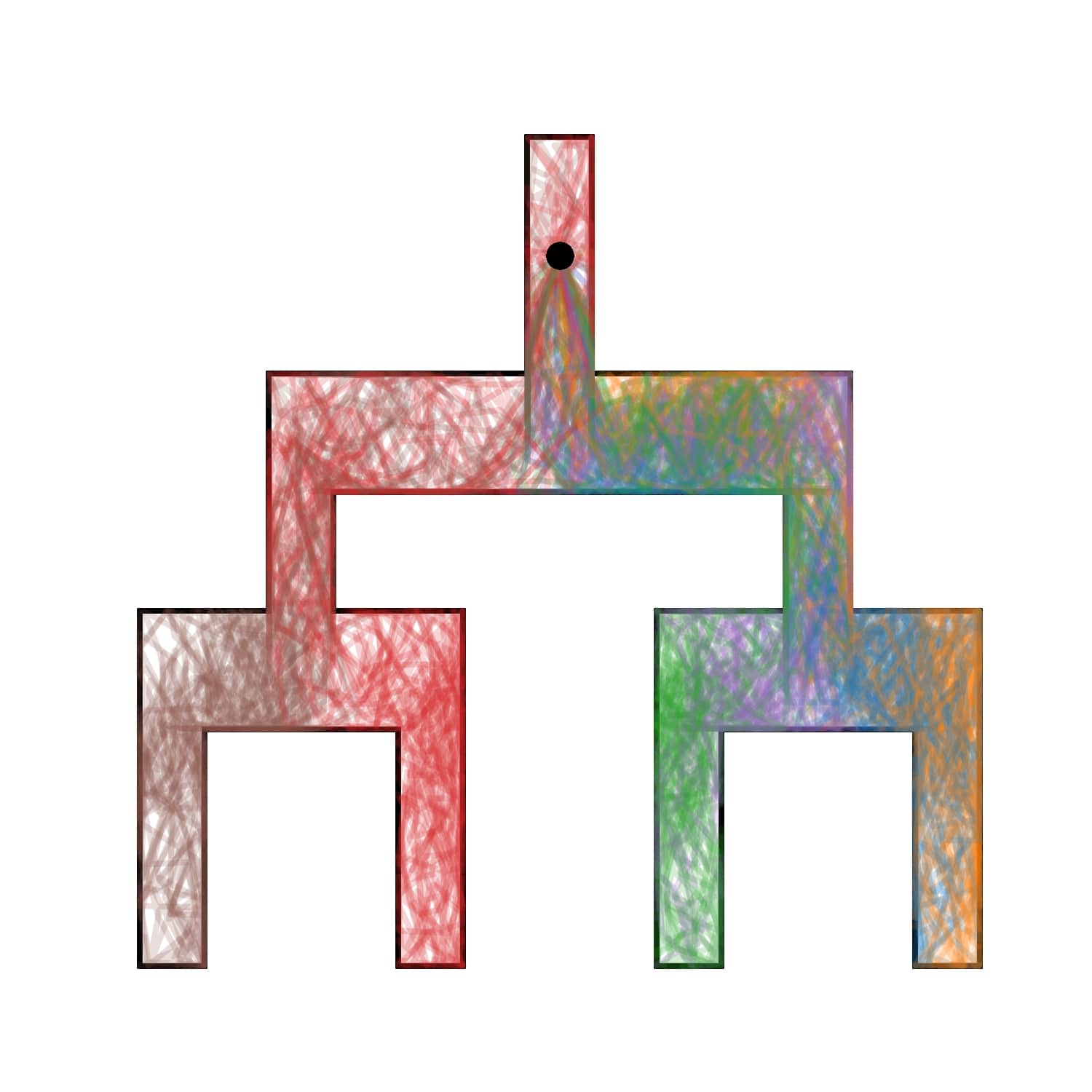
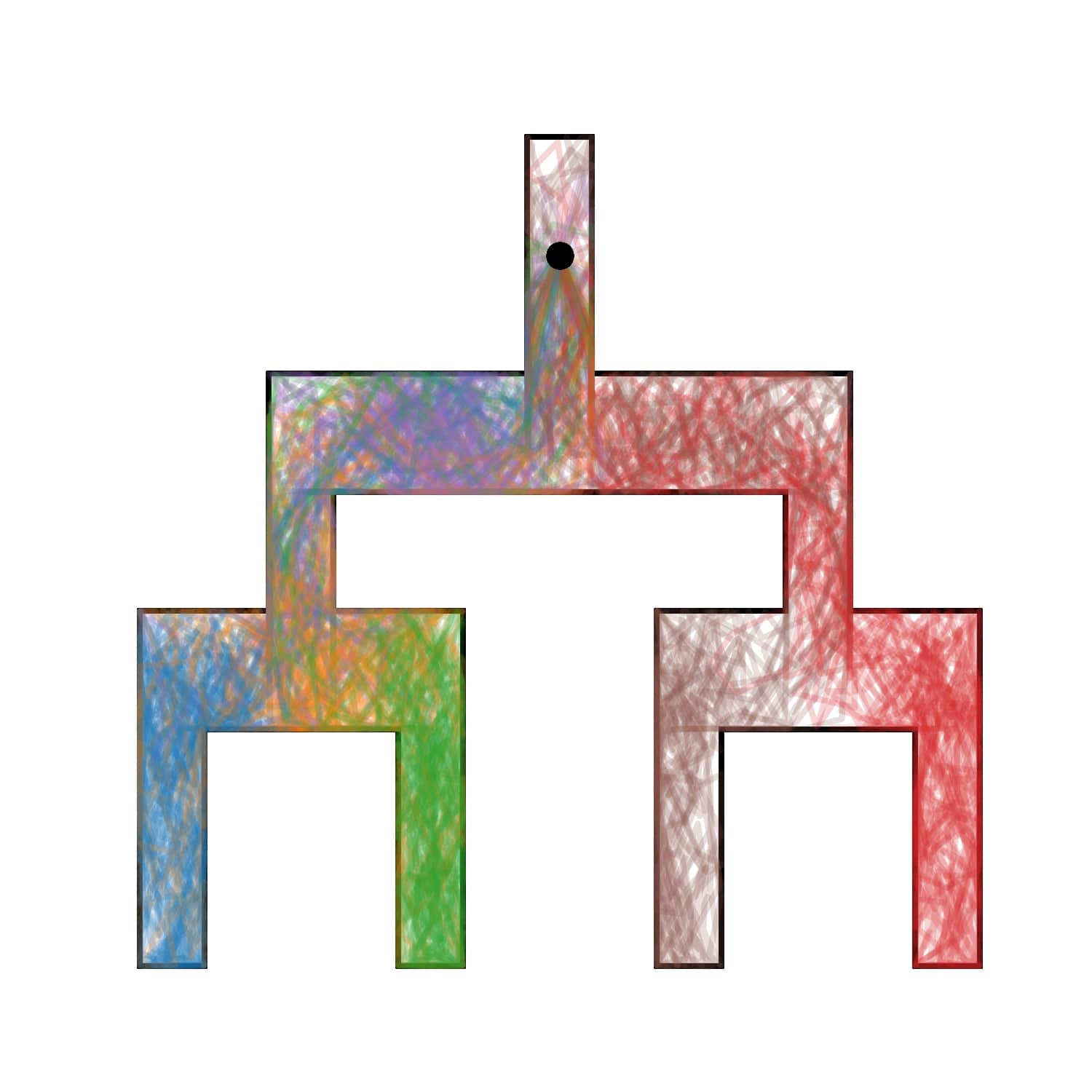
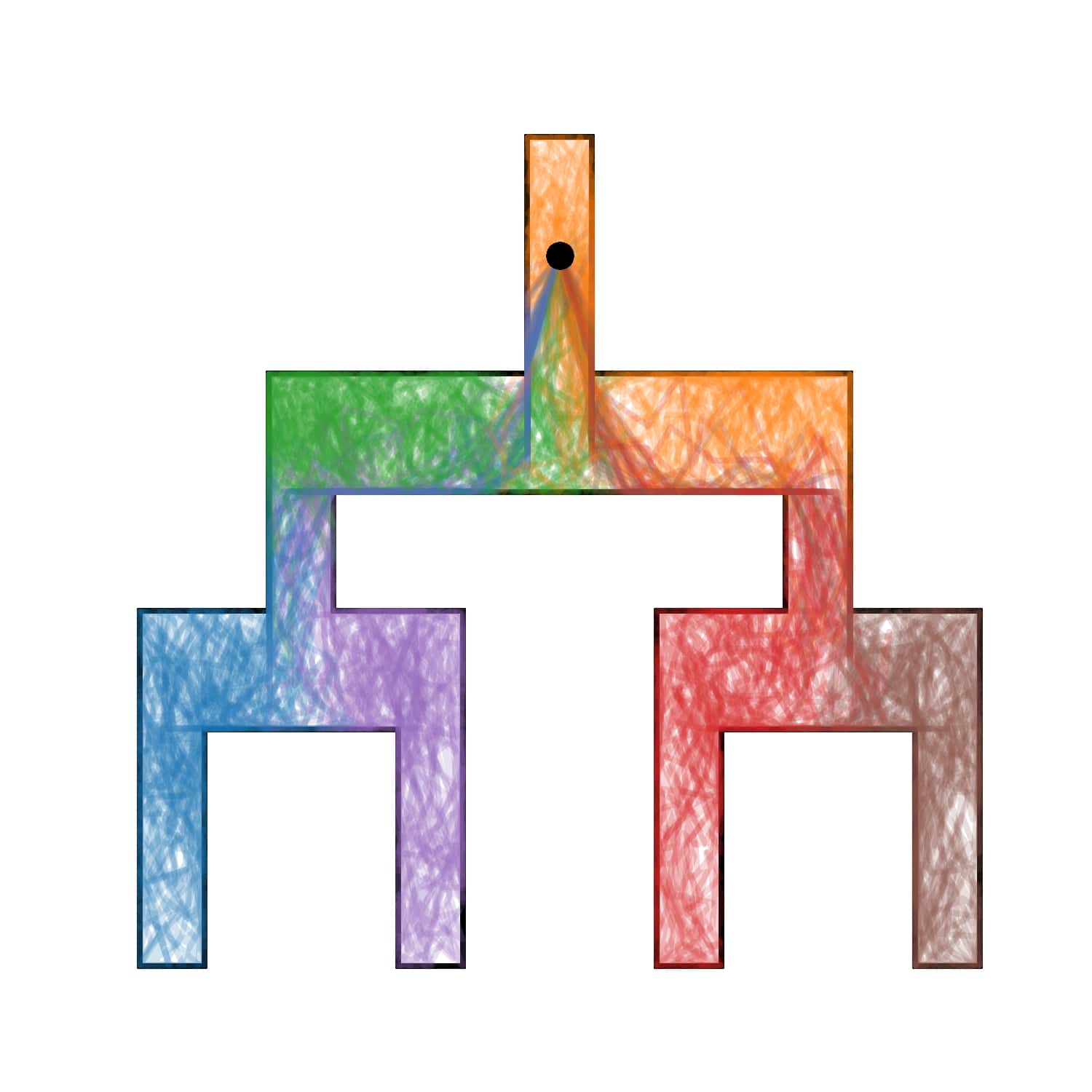



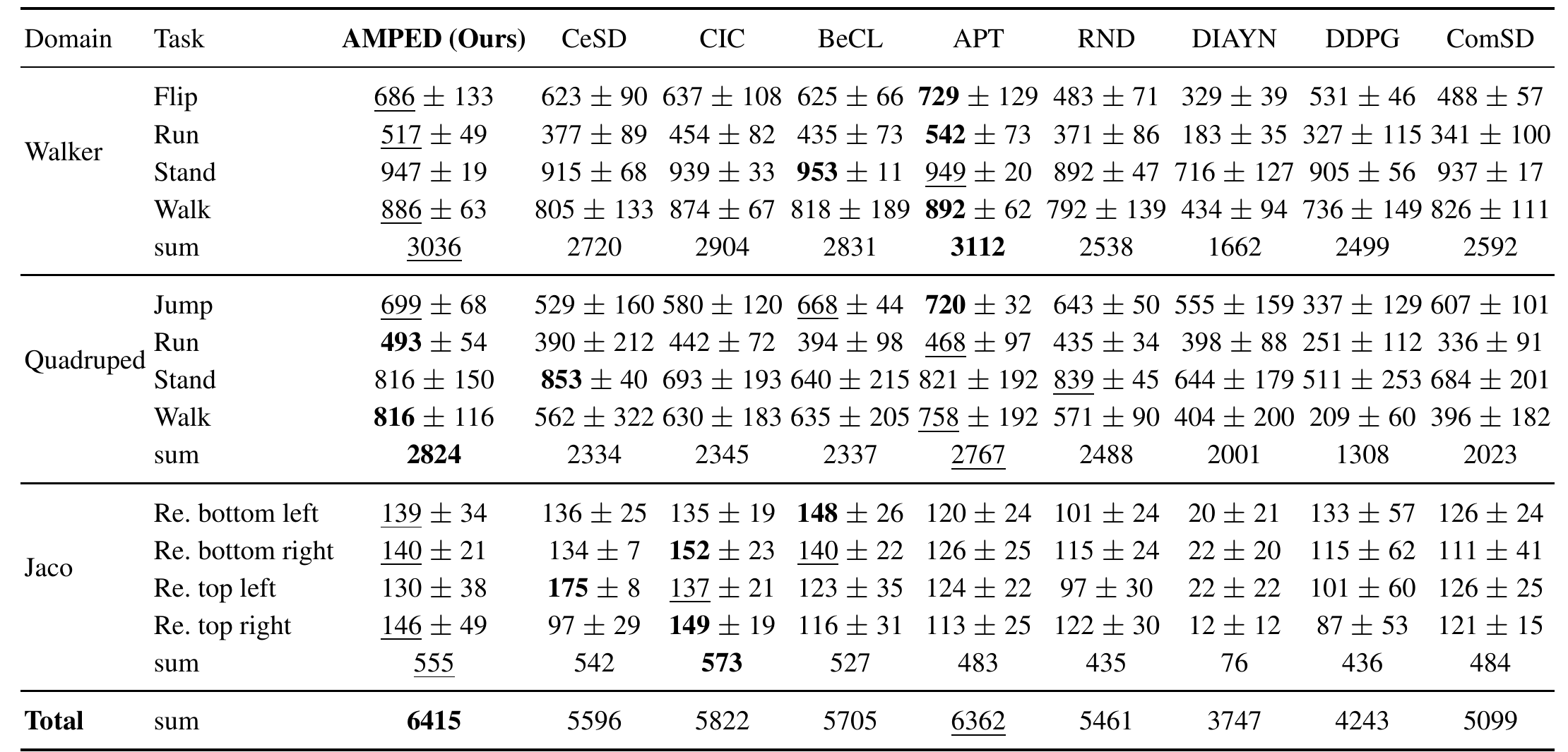
3. Quantitative Evaluation on URLB
🔍 Click to view the full table
We evaluate AMPED and prior methods on the Unsupervised Reinforcement Learning Benchmark (URLB) using four key metrics: Median, Interquartile Mean (IQM), Mean, and Optimality Gap, all measured via expert-normalized scores.
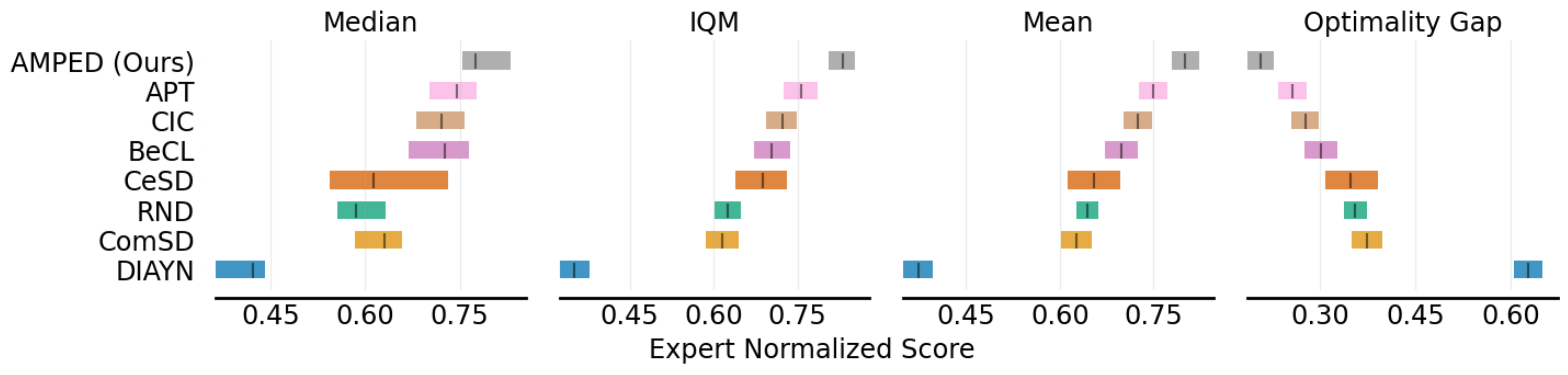
Notably, AMPED ranks first in all four metrics, highlighting both its consistency and effectiveness across a wide range of tasks. It significantly outperforms prior methods like BeCL, CeSD, ComSD, and DIAYN, particularly in terms of IQM and optimality gap.
4. How important is each component of AMPED?
🔍 Click to view Component Ablation Table
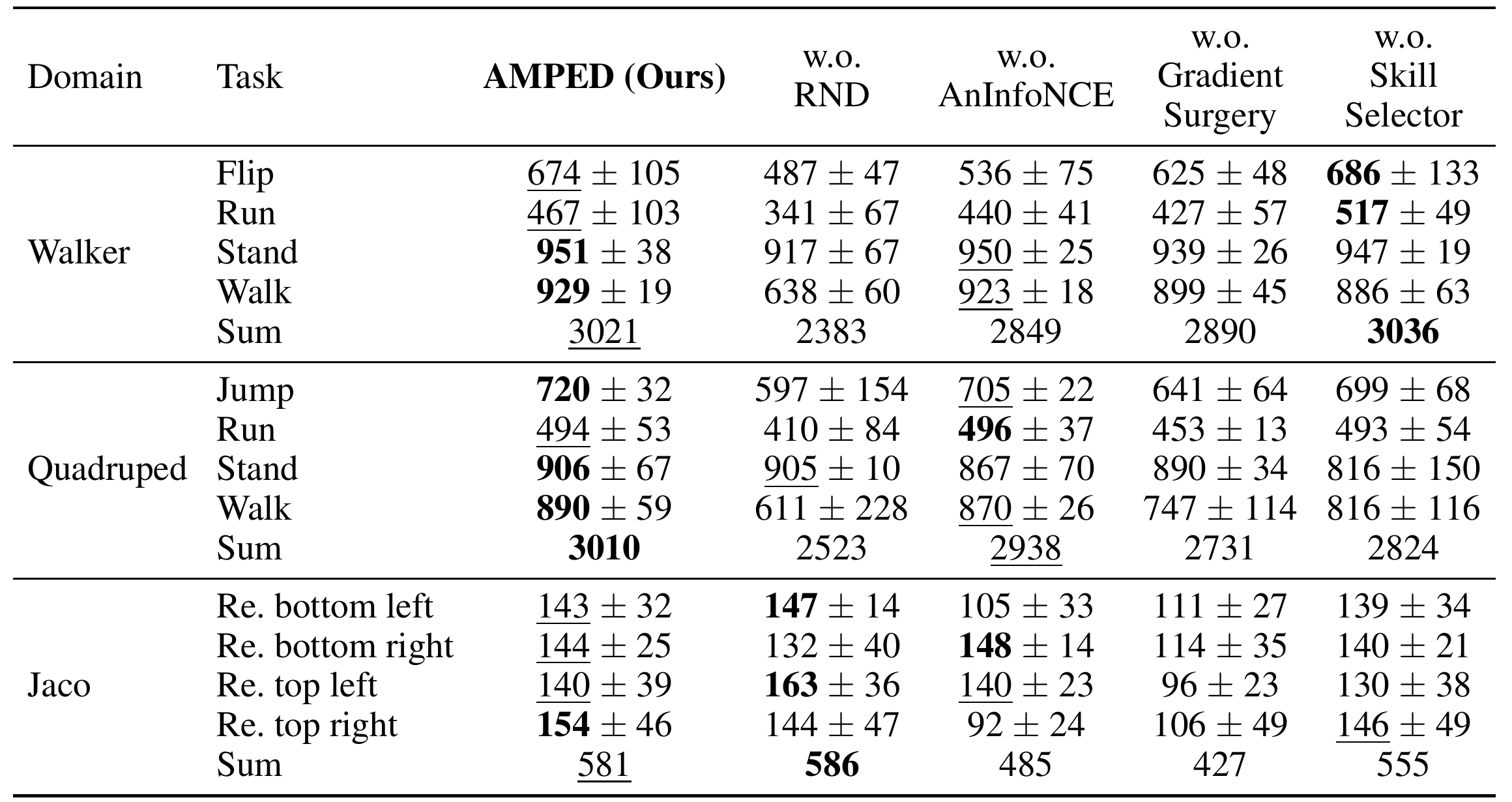
We conduct ablation experiments by systematically removing each core component of AMPED: RND-based exploration, AnInfoNCE-based diversity, gradient surgery, and the skill selector. The performance is evaluated across three domains (Walker, Quadruped, Jaco) with four tasks each.
Removing RND or gradient surgery leads to the most significant performance degradation, particularly in locomotion-heavy environments like Walker and Quadruped. AnInfoNCE and skill selector also contribute meaningfully, but to a lesser degree. This highlights the importance of each component in achieving AMPED's superior performance.
5. How fast is AMPED?
🔍 Click to view Pretraining Time Table

We compare the wall-clock training time of AMPED with various baselines across the Walker, Quadruped, and Jaco domains. Despite achieving superior downstream performance, AMPED introduces only a modest runtime overhead compared to competitive methods such as CeSD and BeCL. Overall, these results indicate that AMPED achieves a favorable trade-off between computational cost and empirical performance.
6. What is the effect of the gradient projection ratio?
We conduct an ablation study to investigate the effect of the gradient projection ratio, that is, the probability of projecting diversity gradients onto the exploration gradient direction when their dot product is negative.
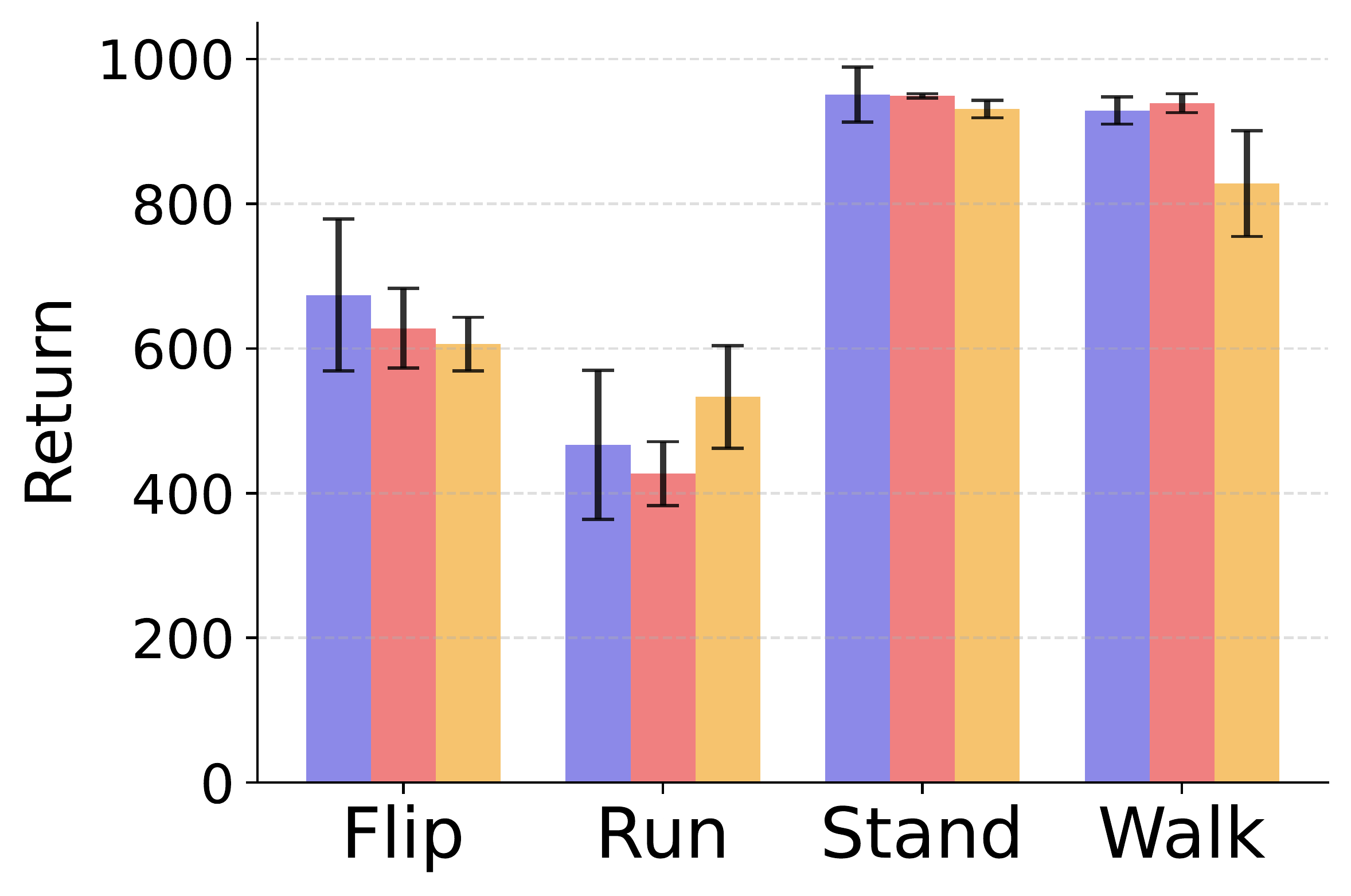
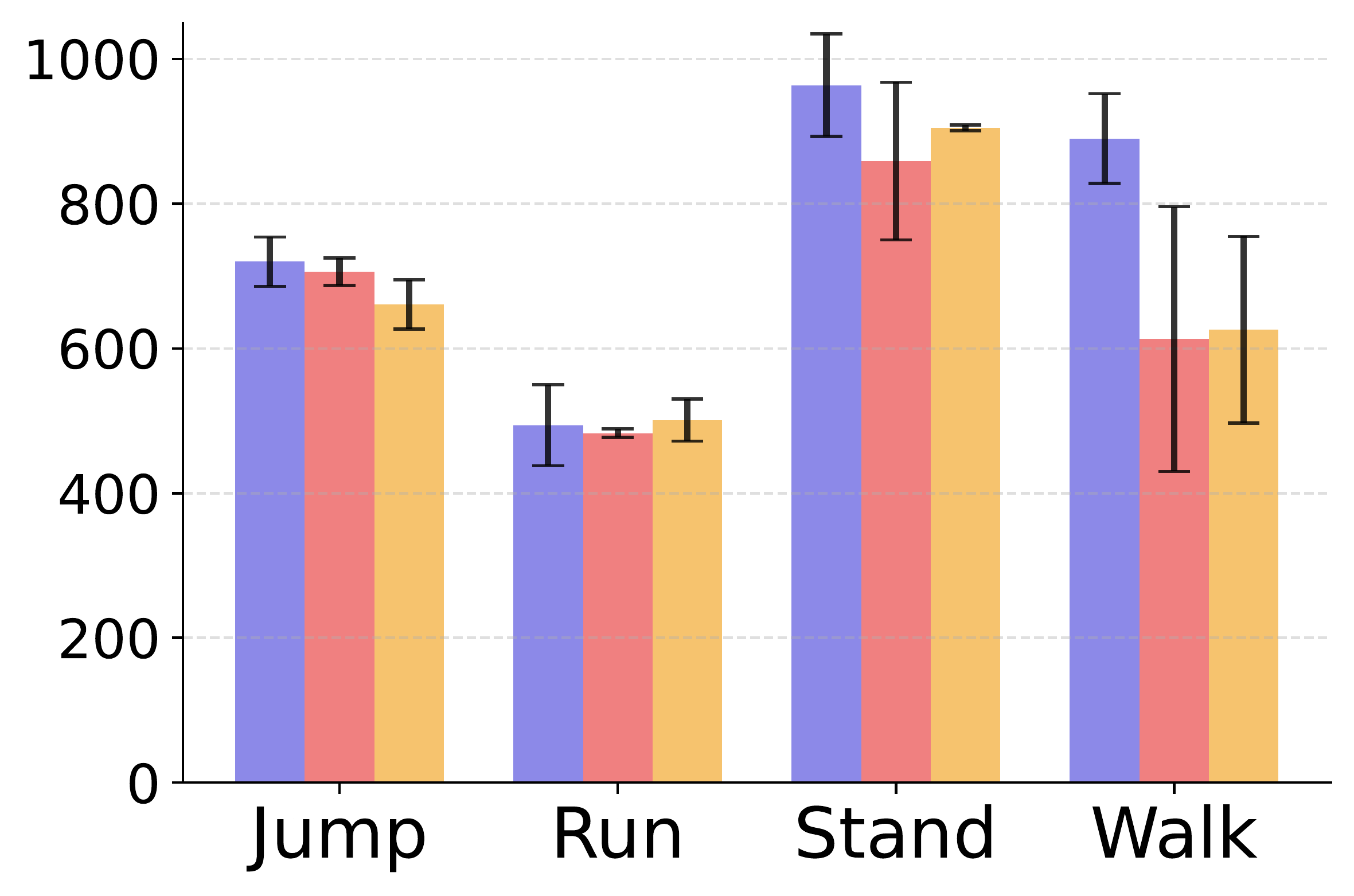
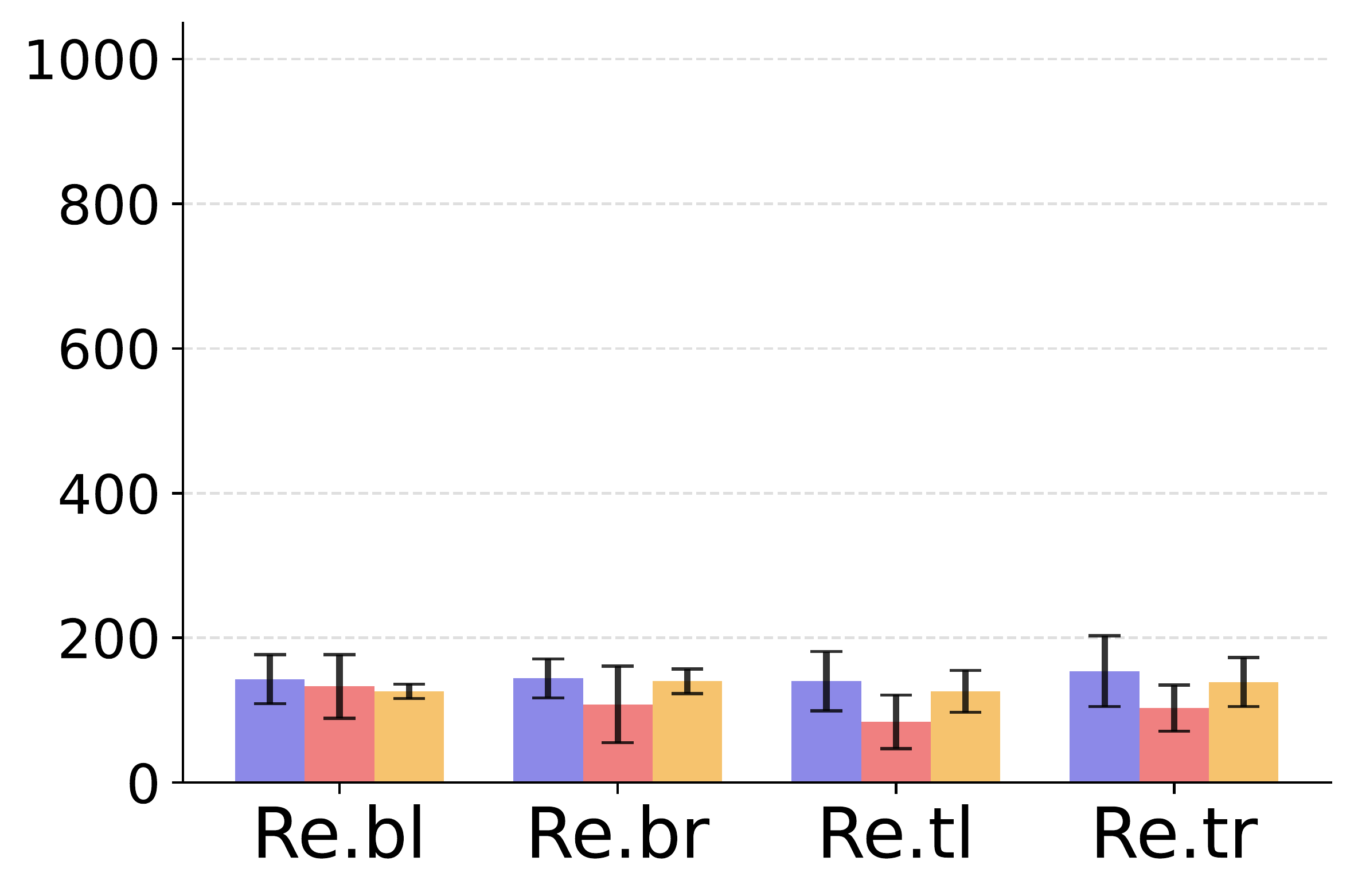
We find that a moderate projection ratio offers the best trade-off between diversity and exploration. A ratio that is too low disables effective gradient alignment, leading to degraded performance, while a ratio that is too high may overly constrain exploration and limit skill diversity.